Typing and Deduping
This page refers to new functionality added by Destinations V2. Typing and deduping is the default method of transforming datasets within data warehouse and database destinations after they've been replicated. Please check each destination to learn if Typing and Deduping is supported.
What is Destinations V2?
Airbyte Destinations V2 provide:
- One-to-one table mapping: Data in one stream will always be mapped to one table in your data warehouse. No more sub-tables.
- Improved per-row error/change handling with
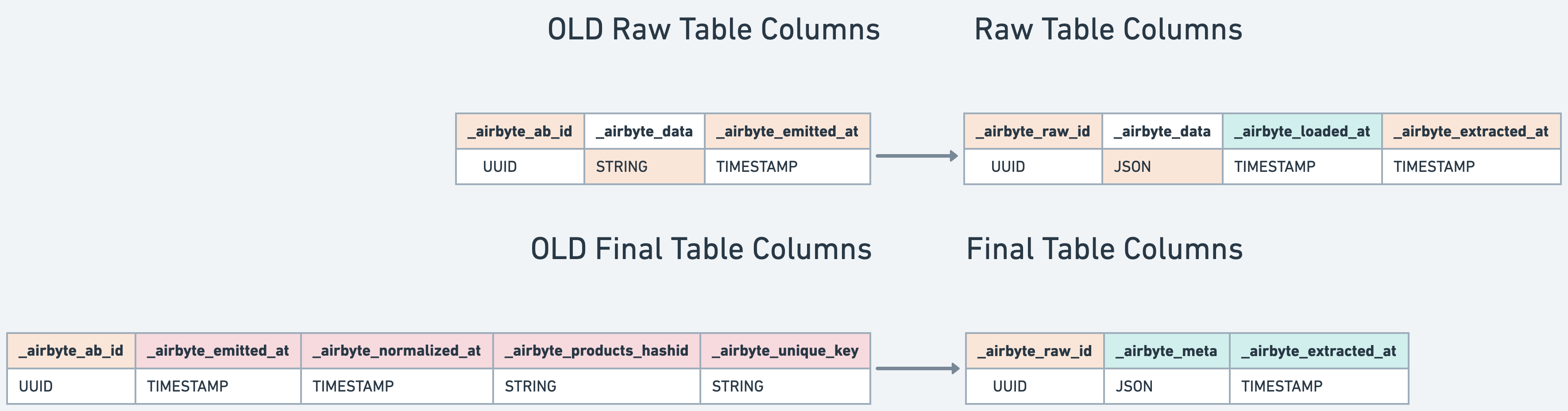
_airbyte_meta: Airbyte will now populate typing changes in the_airbyte_metacolumn instead of failing your sync. You can query these results to audit misformatted or unexpected data. - Internal Airbyte tables in the
airbyte_internalschema: Airbyte will now generate all raw tables in theairbyte_internalschema. We no longer clutter your desired schema with raw data tables. - Incremental delivery for large syncs: Data will be incrementally delivered to your final tables when possible. No more waiting hours to see the first rows in your destination table.
_airbyte_meta Changes
"Per-row change handling" is a new paradigm for Airbyte which provides greater flexibility for our
users. Airbyte now separates data-moving problems from data-content problems. Prior to
Destinations V2, both types of errors were handled the same way: by failing the sync. Now, a failing
sync means that Airbyte could not move all of your data. You can query the _airbyte_meta column
to see which rows failed for content reasons, and why. This is a more flexible approach, as you
can now decide how to handle rows with errors/changes on a case-by-case basis.
When using data downstream from Airbyte, we generally recommend you only include rows which do not have an change, e.g:
-- postgres syntax
SELECT COUNT(*) FROM _table_ WHERE json_array_length(_airbyte_meta ->> changes) = 0
The types of changes which will be stored in _airbyte_meta.changes include:
- Typing changes: the source declared that the type of the column
idshould be an integer, but a string value was returned. - Size changes: the source returned content which cannot be stored within this this row or column (e.g. a Redshift Super column has a 16mb limit). Destinations V2 will allow us to trim records which cannot fit into destinations, but retain the primary key(s) and cursors and include "too big" changes messages.
Also, sources can make use of the same tooling to denote that there was a problem emitting the Airbyte record to begin with,
possibly also creating an entry in _airbyte_meta.changes.
Depending on your use-case, it may still be valuable to consider rows with changes, especially for
aggregations. For example, you may have a table user_reviews, and you would like to know the count
of new reviews received today. You can choose to include reviews regardless of whether your data
warehouse had difficulty storing the full contents of the message column. For this use case,
SELECT COUNT(*) from user_reviews WHERE DATE(created_at) = DATE(NOW()) is still valid.
Destinations V2 Example
Consider the following source schema for stream users:
{
"id": "number",
"first_name": "string",
"age": "number",
"address": {
"city": "string",
"zip": "string"
}
}
The data from one stream will now be mapped to one table in your schema as below:
Final Destination Table Name: public.users
| (note, not in actual table) | _airbyte_raw_id | _airbyte_extracted_at | _airbyte_meta | id | first_name | age | address |
|---|---|---|---|---|---|---|---|
| Successful typing and de-duping ⟶ | xxx-xxx-xxx | 2022-01-01 12:00:00 | {} | 1 | sarah | 39 | { city: “San Francisco”, zip: “94131” } |
| Failed typing that didn’t break other rows ⟶ | yyy-yyy-yyy | 2022-01-01 12:00:00 | { changes: {"field": "age", "change": "NULLED", "reason": "DESTINATION_TYPECAST_ERROR"}} | 2 | evan | NULL | { city: “Menlo Park”, zip: “94002” } |
| Not-yet-typed ⟶ |
In legacy normalization, columns of
Airbyte type Object in the Destination
were "unnested" into separate tables. In this example, with Destinations V2, the previously unnested
public.users_address table with columns city and zip will no longer be generated.
Raw Destination Table Name: airbyte_internal.raw_public__users (airbyte_internal.raw_{namespace}__{stream})
| (note, not in actual table) | _airbyte_raw_id | _airbyte_data | _airbyte_loaded_at | _airbyte_extracted_at |
|---|---|---|---|---|
| Successful typing and de-duping ⟶ | xxx-xxx-xxx | { id: 1, first_name: “sarah”, age: 39, address: { city: “San Francisco”, zip: “94131” } } | 2022-01-01 12:00:001 | 2022-01-01 12:00:00 |
| Failed typing that didn’t break other rows ⟶ | yyy-yyy-yyy | { id: 2, first_name: “evan”, age: “fish”, address: { city: “Menlo Park”, zip: “94002” } } | 2022-01-01 12:00:001 | 2022-01-01 12:00:00 |
| Not-yet-typed ⟶ | zzz-zzz-zzz | { id: 3, first_name: “edward”, age: 35, address: { city: “Sunnyvale”, zip: “94003” } } | NULL | 2022-01-01 13:00:00 |
You also now see the following changes in Airbyte-provided columns:
On final table re-creation
From time to time, Airbyte will drop and re-create the final table produced by a sync (sometimes called a "soft reset"). This is done as transactionally as possible, and should be invisible to most observers. This is done for a number of reasons, including:
- Schema Migrations - Many destinations lack the ability to control column order, or cannot alter one data type to another. Re-creating the table allows Airbyte to strictly control the column order and data types of each column.
- Transactional Full Refresh - In order to keep your final tables consistently useful, when a refresh or reset occurs, airbyte will erase the raw tables, and then build a new tmp final table first. Airbyte attempts to do an atomic swap of old and tmp final tables, usually via a rename at the last second. Otherwise, there would be a period of time where the final table is empty, which could cause downstream issues.
This means that additional permissions, constraints, views, or other rules you apply to the final table outside of Airbyte could be lost during a sync. Many destinations provide ways to use roles or wildcards to grant permissions to tables, which are better suited for this ELT process. We do not recommend altering the final tables (e.g. adding constraints) as it may cause issues with the sync.
Manually triggering a final table re-creation
In some cases, you need to manually run a soft reset - for example, if you accidentally delete some records from the final table and want to repopulate them from the raw data. This can be done by:
- Dropping the final table entirely (
DROP TABLE <your_final_table>) - Unsetting the raw table's
_airbyte_loaded_atcolumn (UPDATE airbyte_internal.<your_raw_table> SET _airbyte_loaded_at = NULL)- If you are using a nonstandard raw table schema, replace
airbyte_internalwith that schema.
- If you are using a nonstandard raw table schema, replace
- And then running a sync.
After the sync completes, your final table will be restored to its correct state.
Loading Data Incrementally to Final Tables
Typing and Deduping may cause an increase in your destination's compute cost. This cost will vary depending on the amount of data that is transformed and is not related to Airbyte credit usage. Enabling loading data incrementally to final tables may further increase this cost.
V2 destinations may include the option "Enable Loading Data Incrementally to Final Tables". When enabled your data will load into your final tables incrementally while your data is still being synced. When Disabled (the default), your data loads into your final tables once at the end of a sync. Note that this option only applies if you elect to create Final tables.